Simulating memory load with fio
Recently at work I was tasked with simulating the workload of a client’s infrastructure consisting of several virtual machines. For our use case, this turned out to be a largely solved problem, thanks to existing tools like fio.
For those who don’t know it, fio is a simple yet powerful program that allows simulating various kinds of I/O workloads. Its simplicity stems from two basic facts: (1) it’s a standalone, CLI executable and (2) it uses plain INI files to define workloads. It’s also powerful because of its extensibility: thanks to I/O engines, it’s not limited to just I/O simulation.
For example, here’s what a CPU-bound workload could look like, using the cpuio engine:
# File: burn-my-cpu.fio
[burn-my-cpu]
# Don't transfer any data, just burn CPU cycles
ioengine=cpuio
# Load the CPU at 100%
cpuload=100
# Make four clones of this job. In a multiprocessor system,
# these are run concurrently on multiple CPUs.
numjobs=4
You can run it with the command:
fio burn-my-cpu.fio
The interesting thing here—beyond the fact that we’re stressing the CPU with an I/O simulation tool—is numjobs=4, which instructs fio to fork four processes—or rather, jobs, in fio lingo—executing the same workload. One could also play with the reserved variable $ncpus to load the desired number of CPUs based on the system at hand.
OK, so fio is capable of generating both I/O and CPU workloads. What about memory? Specifically, how can we simulate a certain amount of memory being allocated for a period of time? Note that here I’m not interested in the simulation of specific read/write patterns; if that’s the case for you, time to close this browser tab I guess.
After a bit of trial and error, I came up with the solution below. I’m not saying that it’s perfect or the right way to do it, but according to my tests™ it does the job:
# File: fill-my-memory.fio
[fill-my-memory]
# This may be omitted, as it's already the default
ioengine=psync
# Just read, don't write anything
readwrite=read
# Read from /dev/zero to avoid disk I/O
filename=/dev/zero
# Read 1GiB into memory
size=1g
# Pin 1GiB of memory with mlock(2)
# This prevents memory from being paged to the swap area
lockmem=1g
# Normally, once the specified size is read, the job terminates
# To keep it running, we set the run time explicitly
time_based=1
runtime=5m
# Stall the job after it has finished reading 1GiB
# This avoids wasting CPU cycles
thinktime=1s
Don’t worry, I’ll try to explain everything in a moment (if comments haven’t already).
Starting from the top, the I/O engine used is psync, for the simple reason that it happens to be the default (in fact, we can even omit that line in the INI file). And since it appears to be a good fit for our use case, I didn’t feel the need to change it. If you’re concerned about what psync actually does, you may want to look at pread(2)’s man page, since that’s what psync leverages behind the scenes. Here’s an excerpt:
pread() reads up to count bytes from file descriptor fd at offset (from the start of the file) into the buffer starting at buf.
So far, so good.
The line readwrite=read tells fio the type of I/O we want to perform. Because we just want to allocate memory, it makes sense to simply read data into it. This is the default behavior, but sometimes explicit is better than implicit1.
Now come the interesting bits. First, there’s filename=/dev/zero, which is a bit of a hack to avoid reading from a real file stored on disk. Not a big deal, but since we’re interested in just allocating a bunch of memory, why doing I/O at all? Especially if we can easily avoid it.
Then, we use a combination of size=1g and lockmem=1g to read 1GiB worth of zeros into memory and keep that allocated. The need for lockmem can be understood by running the same job without lockmem and inspecting its memory usage, perhaps with top (you may need to tweak its configuration to display the relevant columns). The following figure highlights memory usage when lockmem is not used:
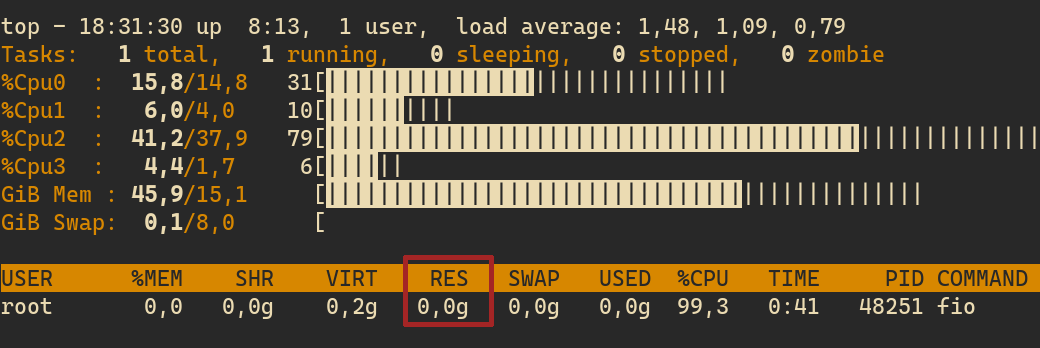
Not all memory is created equal: here we’re interested in the value of the RES column, which stands for resident memory. This value refers to the actual, physical memory being allocated to the process, not counting swap. But how can it be (nearly) zero? I’m not super knowledgeable about the details, but generally speaking, what is happening here is that even though we are requesting to read 1GiB of data into memory, that amount is not wholly loaded into physical memory. Instead, the OS acts as a middleman by effectively loading a fraction of it.
You may appreciate why this default behavior is a good thing for everyone; think about what would happen if every process was able to allocate physical memory at will. Not incidentally, the use of lockmem requires root privileges.
Under the hood, lockmem makes use of the mlock() system call. Once again, man comes to the rescue:
mlock() […] lock[s] part or all of the calling process’s virtual address space into RAM, preventing that memory from being paged to the swap area.
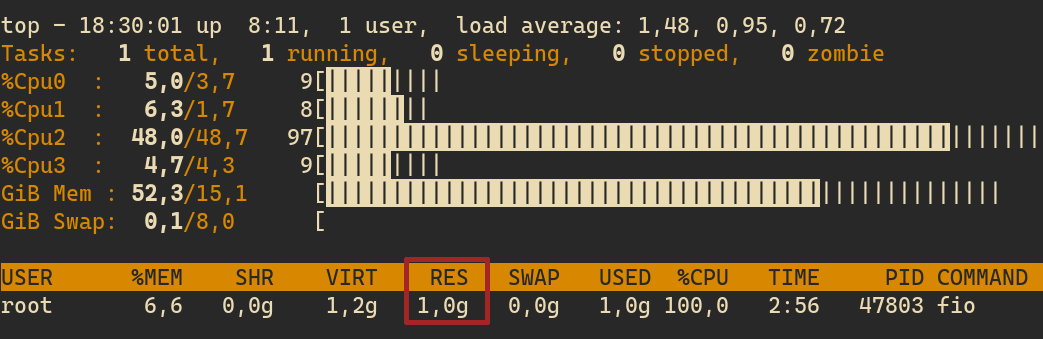
What lockmem essentially does is “pinning” the specified amount of memory to the physical memory. Indeed, if we run the job with lockmem=1g, we can see that this time the RES column reports the expected value:
We then have time_based=1 and runtime=5m, which simply say: “Run this job for five minutes, whether or not we’re done with I/O work”. Seems innocuous, right? Indeed, it does what we expect, but with a caveat: the CPU goes crazy for the entire job duration.
As with the unnecessary disk I/O—which we avoided by reading from /dev/zero—I didn’t like the fact that a job intended to stress the memory generated a substantial amount of CPU workload. I think it’s good to keep things isolated so that we can test them independently.
After digging a bit in fio’s manual, my attention was drawn to the description of the time_based parameter:
If set, fio will run for the duration of the runtime specified even if the file(s) are completely read or written. It will simply loop over the same workload as many times as the runtime allows.
If I understand it correctly, the job is busy reading from /dev/zero over and over, even after the initial read of 1GiB is complete. This inevitably puts a toll on the CPU.
Fortunately, fio is a goldmine of parameters. In the last line of our workload definition, there’s this option called thinktime, which, according to the manual, allows to “stall a job for the specified period of time after an I/O has completed before issuing the next”. I discovered that setting thinktime to any value that is not in microseconds, causes the job to stall indefinitely—unless time_based and runtime are also set, in which case the job is stopped after a fixed interval. While this is exactly what we want, I’m not sure why fio behaves like that. Even if we agree that thinktime should stall the job indefinitely—because there’s no job to issue next—why should the chosen unit of time matter?
Anyway, here’s an interesting comparison between the job running without and with thinktime set:
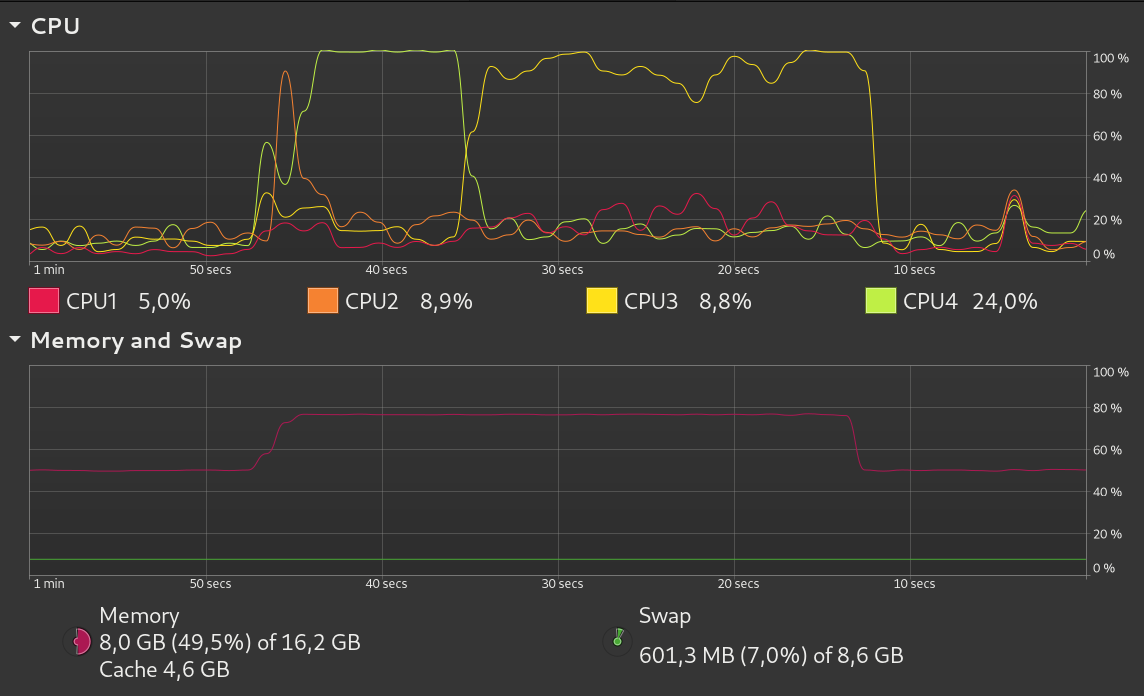
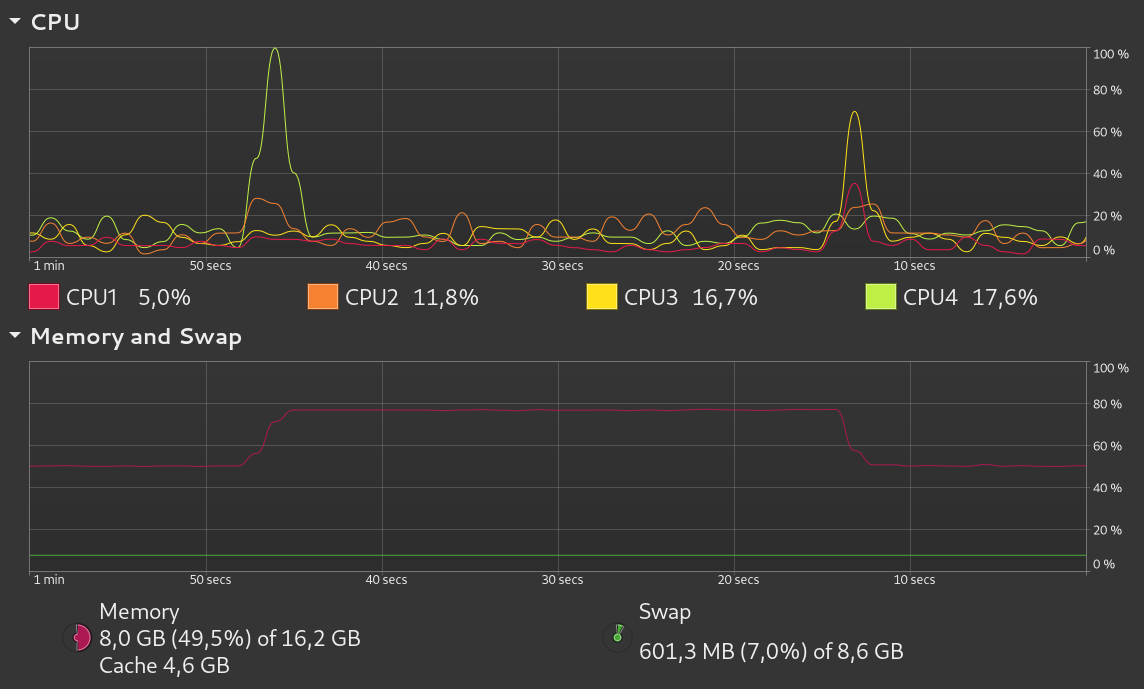
For the purpose of this visualization, I set runtime=30s and size=4g. You can see that with thinktime=1s, the CPU is doing a significant amount of work only at the beginning and at the end of the job runtime, presumably because it’s busy loading/unloading data to/from memory.
Ouch! Seems we’ve hit EOF. Don’t forget to run fio as root, because lockmem needs it. I hope this post brought something new to the table!